








У микроконтроллеров AVR, по сути, имеется два пути реализации умножения, разница между которыми заключается в форме представления произведения и, соответственно, в различии выполняемых арифметических операций. Первый оптимизирован для использования с командой однобайтового умножения, второй – использует только сложение и сдвиговые операции. Для произведения n-разрядного множимого и m-разрядного множителя необходимо отводить n+m разрядов.
Помимо этого существует особый случай умножения на целую степень 2. Всё дело в том, что 2 является основанием двоичной системы, а в любой позиционной системе операция умножения числа на основание системы приводит к увеличению веса каждого его разряда на порядок:
2*X = 2*(xn-1*2n-1 + xn-2*2n-2 + … + x1*21 + x0*20) = xn-1*2n + xn-2*2n-1 + … + x1*22 + x0*21.
Как видно, коэффициенты xn числа X переместились на один разряд влево (x0 стал при 21, x1 стал при 22 и т.д.). Итак, для умножения двоичного числа на 2n необходимо просто сдвинуть его на n разрядов влево. Так можно осуществить умножение на 2 двухбайтового числа в регистрах R17:R16 посредством сдвиговых операций:
lsl R16 ;R16 <- R16 << 1 (LSB <- 0, флаг С <- MSB)
rol R17 ;R17 <- R17 << 1 (LSB <- флаг С, флаг С <- MSB)
Тот же результат можно получить, складывая число с самим собой:
add R16, R16
adc R17, R17
Благодаря тому, что операции сдвига и сложения выполняются за одинаковое время (1 машинный цикл) оба примера равноценны.
Иногда встречаются операции умножения на число, которое близко к степени 2. В таких случаях намного проще заменить его суммой двух слагаемых, одно из которых кратно 2n, и использовать только операции сдвига и сложения (вычитания):
63*X = (26-1)*X = 26*X - X = X<<6 – X,
33*X = (25+1)*X = 25*X + X = X<<5 + X,
130*X = (27+2)*X = 27*X + 2*X = X<<7 + X<<2.
Для умножения 2-байтовых чисел (обозначим их как XH:XL = 28*XH + XL и YH:YL = 28*YH + YL) применяется следующая вычислительная схема:
XH:XL * YH:YL = (28*XH + XL)*(28*YH + YL) = 216*XH*YH + 28*(XH*YL + YH*XL) + XL*YL.
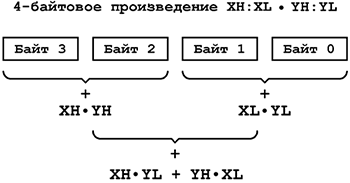
Рис.1 Вычислительная схема для умножения двухбайтовых чисел с использованием инструкции умножения
Отыскание 32-разрядного результата сводится к последовательности операций однобайтовых умножений и последующего сложения всех произведений с учётом сдвига слагаемых XH*YL, XL*YH на 1 байт и XH*YH на 2 байта, как показано на рис.1. Подпрограмма, реализующая эти действия, приведена ниже. Напомним, что произведение двух однобайтовых множителей, полученное в результате выполнения команды mul Rd,Rr или любой другой команды умножения, всегда заносится в регистровую пару R1:R0.
; R23:R22:R21:R20 = R17:R16 * R19:R18
; R23:R22:R21:R20 - произведение
; R17:R16 – множимое
; R19:R18 – множитель
; R1,R0 – вспомогательные регистры
mul16_16:
mul R16,R18 ;находим XL*YL = R16*R18 и заносим его в
movw R20,R0 ;младшие байты произведения R21:R20
mul R17,R19 ;находим XH*YH = R17*R19 и заносим его в
movw R22,R0 ;старшие байты произведения R23:R22
mul R17,R18 ;находим XH*YL = R17*R18 и прибавляем его к
clr R17 ;байтам R23:R22:R21 произведения
add R21,R0
adc R22,R1
adc R23,R17
mul R16,R19 ;находим YH*XL = R19*R16 и прибавляем его к
add R21,R0 ;байтам R23:R22:R21 произведения
adc R22,R1
adc R23,R17
ret
Возвести двухбайтовое число в квадрат еще проще:
XH:XL * XH:XL = (28*XH + XL)*(28*XH + XL) = 216*XH*XH + 28*2*XH*XL + XL*XL.
Подпрограмма возведения в квадрат приведена ниже. Она является хорошим примером того, где может пригодиться инструкция fmul Rd,Rr, которая одним действием производит умножение двух однобайтовых чисел и сдвиг произведения на 1 разряд влево.
; R21:R20:R19:R18 = R17:R16 * R17:R16
; R17:R16 – число, возводимое в квадрат
; R21:R20:R19:R18 – произведение
; R1,R0 – вспомогательные регистры
sqr16_16:
mul R16,R16 ;находим XL*XL = R16*R16 и заносим его в
movw R18,R0 ;младшие байты произведения R19:R18
mul R17,R17 ;находим XH*XH = R17*R17 и заносим его в
movw R20,R0 ;старшие байты произведения R21:R20
fmul R17,R16 ;находим 2*XH*YL = R17*R18 и прибавляем его
clr R17 ;к байтам R21:R20:R19 произведения
rol R17
add R19,R0
adc R20,R1
adc R21,R17
ret
Во многих случаях команда fmul Rd,Rr позволяет использовать аппаратный умножитель 8x8 фактически как умножитель 9x8 с получением 17-разрядного результата (MSB произведения размещается в C). Это бывает очень полезно, когда возникает необходимость умножить переменную на постоянный числовой коэффициент, который немного выходит за пределы 8-разрядной сетки. Так, допустим, можно умножить число из R16 на 500
ldi R17,250 ;R1:R0 <- (250<<1)*R16 = 500*R16
fmul R17,R16 ; флаг С <- MSB
или на 1000:
ldi R17,250 ;R1:R0 <- (250<<2)*R16 = 1000*R16
fmul R17,R16 ;флаг С <- MSB
lsl R0
rol R1
Ниже показан другой практически важный пример умножения, когда один из множителей (множитель X) однобайтовый. В основе подпрограммы лежит следующая вычислительная схема:
X * YH:YL = X*(28*YH + YL) = 28*X*YH + X*YL
; R21:R20:R19 = R18 * R17:R16
; R21:R20:R19 - произведение
; R18 – множимое
; R17:R16 – множитель
; R1,R0 – вспомогательные регистры
mul8_16:
mul R18,R17 ;находим X*YH = R18*R17 и заносим его в
movw R20,R0 ;старшие байты произведения R21:R20
mul R18,R16 ;находим X*YL = R18*R16
clr R18
add R19,R0 ;и прибавляем его
add R20,R1 ;к произведению R21:R20:R19
adc R21,R18
ret
Точно также могут быть разложены числа и с большей разрядностью. Однако с ростом их величины начинают резко возрастать и затраты ресурсов процессора. Так для умножения трёхбайтовых чисел понадобится по 9 операций однобайтовых умножений и двухбайтовых сложений; для четырёхбайтовых уже по 16 операций и т.д.
В подобных случаях необходимо использовать другой, наиболее общий алгоритм, который не использует команду mul Rd,Rr. А для микроконтроллеров семейства ATtiny, (а также для устаревшей линейки моделей Classic), у которых отсутствует аппаратный умножитель, он вообще является единственно возможным.
Для пояснения алгоритма, перепишем произведение Z двух произвольных двоичных чисел
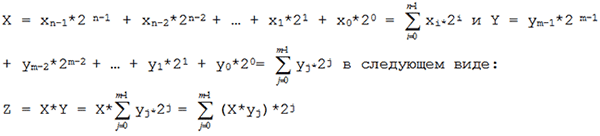
Произведение X*yj называется частичным произведением (X*yj = X при yj =1 и X*yj = 0 при yj =0), а произведение (X*yj)*2j есть не что иное, как частичное произведение, сдвинутое на j разрядов влево. Итак, нахождение произведение X*Y сводится к нахождению суммы частичных произведений X*yj, каждое из которых в свою очередь сдвинуто на j разрядов влево соответственно. На этом принципе основан школьный метод умножения в столбик. Рассмотрим пример умножения двух 4-разрядных чисел:
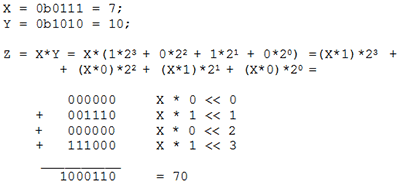
Как видим, для получения результата используются только операции сложения и сдвига. При этом в тех разрядах Y, где yj=0 и X*yj=0. И если предварительно анализировать значения yj/, то можно пропускать пустое сложение с 0 в соответствующих итерациях. Ниже приведена подпрограмма умножения двух трёхбайтовых чисел. В ней для получения суммы частичных произведений, сдвинутых каждое на j разрядов влево, производится сдвиг накопителя произведений m=24 раза вправо, а для экономии памяти младшие 3 байта произведения заносятся в те же регистры, где находился множитель.
; R24:R23:R22:R21:R20:R19 = R18:R17:R16 * R21:R20:R19
; R24:R23:R22:R21:R20:R19 – произведение
; R18:R17:R16 – множимое
; R21:R20:R19 – множитель
; R25,R1,R0 – вспомогательный регистр
mul24_24:
clr R22 ;очищаем регистры R22,R23,R24
clr R23 ;при входе в подпрограмму
clr R24
ldi R25,24 ;инициализируем счётчик циклов сложения
clc ;сдвинутых частичных произведений
ml1: sbrs R19,0 ;если младший бит множителя 1, то
rjmp ml2
add R22,R16 ;добавляем к накопителю очередное
adc R23,R17 ;частичное произведение R18:R17:R16
adc R24,R18
ml2: ror R24 ;байтам R24:R23:R22 накопителя произведения
ror R23 ;в ином случае пропускаем это действие
ror R22 ;и переходим к очередному сдвигу множителя
ror R21
ror R20
ror R19
clc
dec R25 ;повторяем m=24 раз цикл сложения
brne ml1 ;сдвинутых частичных произведений
ret
Перейти к следующей части: Деление
 Котов Игорь Юрьевич
Котов Игорь Юрьевич
 Опубликована: 2012 г.
Опубликована: 2012 г.


 Вознаградить
Вознаградить



Комментарии (1) |
Я собрал (0) |
Подписаться
|
Я собрал (0) |
Подписаться
Для добавления Вашей сборки необходима регистрация