








Структура типичной программы предполагает, что все задачи разделяют единое пространство памяти и каждая из них, если понадобится, может иметь доступ к любым ресурсам процессора. Такое ее устройство обладает рядом недостатков, особенно существенных на этапе разработки и отладки приложения. Из них главная проблема – это невозможность избавится от тесной взаимосвязи всех элементов программы. С ростом объема исполняемого кода становится все труднее контролировать влияние разных параметров на логику работы. Любая малозаметная ошибка может привести к полной неработоспособности всей программы или, что еще хуже, к различным дефектам работы уже в процессе эксплуатации изделия. Таких неприятностей можно избежать, если использовать операционную систему с переключением задач или операционную систему реального времени (ОСРВ).
Принцип действия ОСРВ
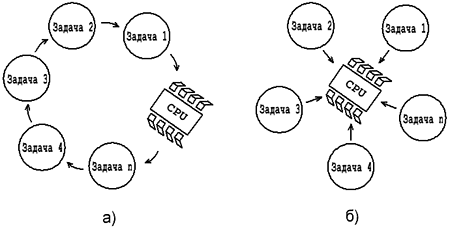
Рис.1 Порядок выполнения задач
а - программа с обыкновенной структурой
б - программа с использованием ОСРВ
По своей сути ОСРВ – это программа, которая организует работу процессора таким образом, что все выполняемые им задачи оказываются разделенными во времени и выполняются каждая в своем собственном адресном пространстве. На рис.1 наглядно показана разница между ходом выполнения обычной программы(а) и той, которая использует ОСРВ(б). В первом случае все задачи выполняются последовательно. Пока одна из них не будет выполнена до конца, другая не начнется. Естественно, что любая программная ошибка, скажется на работоспособности всего приложения, а “зависание” на каком-либо этапе вообще приведет к полной остановке. В ОСРВ все совсем по-другому. Здесь каждая задача получает для своего выполнения лишь отведенный ей временной интервала (квант времени). По истечению этого временного промежутка работа текущей задачи приостанавливается и процессор переходит к выполнению следующей в списке задачи и т.д. Таким образом, появляется возможность не только полностью контролировать время выполнения каждой задачи (вплоть до ее остановки), но и вести программный контроль над ошибками. К тому же во время разработки можно будет применить модульный подход, когда отдельные участки программы тестируются, независимо друг от друга.
.include "m8def.inc"
.equ DELAY = 100 ;задержка времени
.def temp = R16 ;регистр для промежуточных операций
.def mask1 = R17 ;временный регистр для задачи 1
.def mask2 = R18 ;временный регистр для задачи 2
.def cnt1 = R19 ;счетчик циклов для задачи 1
.def cnt2 = R20 ;счетчик циклов для задачи 2
.def tsknum = R21 ;регистр хранения номера текущей задачи
.def zero = R23 ;регистр с нулевым содержимым
.def templ = R24 ;регистры для промежуточных операций при
.def temph = R25 ;сохранении и восстановлении адреса возврата
.dseg
.org 0x060
adr1h: .byte 1 ;старший байт адреса возврата в задачу 1
adr1l: .byte 1 ;младший байт адреса возврата в задачу 1
adr2h: .byte 1 ;старший байт адреса возврата в задачу 2
adr2l: .byte 1 ;младший байт адреса возврата в задачу 2
.cseg
.org 0
rjmp initial
.org 0x0009
rjmp service_T0OVER
.org 0x0020
initial:
ldi temp,high(RAMEND) ;инициализация стека на SP = 0x045F
out SPH,temp
ldi temp,low(RAMEND)
out SPL,temp
sbi DDRB,DDB0 ;установка линии 0 порта B на вывод
sbi DDRB,DDB1 ;установка линии 1 порта B на вывод
ldi temp,(1«CS02)|(1«CS00) ;включение таймера 0 с
out TCCR0,temp ;предделителем F/1024
ldi temp,1«TOIE0 ;разрешение прерывания по переполнению
out TIMSK,temp ;таймера 0 (период T = F/1024/256)
ldi temp,high(task2) ;загрузка в adr2h:adr2l начального
sts adr2h,temp ;адреса возврата task2 = 0x0200
ldi temp,low(task2)
sts adr2l,temp
ldi tsknum,1 ;заносим номер текущей задачи
clr zero
sei ;глобальное разрешение прерываний
rjmp task1 ;переходим к выполнению задачи 1
.org 0x0100
task1: ; PC SP
in temp,PORTB
ldi mask1,1«PB0
eor mask1,temp
out PORTB,mask1
ldi cnt1,DELAY ;0x0104 0x045F <- Прерывание 1
lp1: dec cnt1 ;0x0105 0x045F <- Выход из прерывания 2
cpse cnt1,zero
brne lp1
rjmp task1
.org 0x0200
task2:
in temp,PORTB ;0x0200 0x045F <- Выход из прерывания 1
ldi mask2,1«PB1
eor mask2,temp
out PORTB,mask2
ldi cnt2,DELAY/2
lp2: dec cnt2 ;0x0205 0x045F <- Прерывание 2
cpse cnt2,zero
brne lp2
rjmp task2
.org 0x0300
service_T0OVER:
pop temph ;извлечение из стека адреса возврата
pop templ ;текущуей задачи в регистры temph:templ
cpi tsknum,1
brne sr1
sts adr1h,temph ;если прерывание возникло при выполнении
sts adr1l,templ ;задачи 1, то сохраняем адрес возврата в
lds temph,adr2h ;adr1h:adr1l и заносим во временные
lds templ,adr2l ;регистры temph:templ адрес возврата в
ldi tsknum,2 ;задачу 2
rjmp sr2
sr1: sts adr2h,temph ;если прерывание возникло при выполнении
sts adr2l,templ ;задачи 2, то сохраняем адрес возврата в
lds temph,adr1h ;adr2h:adr2l и заносим во временные
lds templ,adr1l ;регистры temph:templ адрес возврата в
ldi tsknum,1 ;задачу 1
sr2: push templ ;загрузка в стек нового адреса возврата
push temph ;из временных регистров temph:templ
reti
Механизм реализации ОСРВ с ядром AVR проиллюстрирован выше. Это листинг программы с переключением двух задач. Первая из них изменяет состояние линии 0 порта ввода-вывода B; вторая делает то же самое с линией 1 порта B, но с удвоенной частотой. Период следования импульсов определяет чикл задержки в теле каждой задачи.
Итак, необходимо добиться попеременного выполнения двух задач. Но в нашем случае это невозможно сделать простыми средствами. Сразу после инициализации процессор войдет в цикл задачи 1 (начинается с метки task1 по адресу 0x0100) и будет там оставаться до самого окончания работы. В теле цикла нет инструкций переходов и вызовов подпрограмм. Именно поэтому в структуре программы задействован еще и таймер-счетчик 0, который при переполнении циклически генерирует прерывания (коэффициент деления предделителя выбран произвольно). На обработчик прерывания (service_T0OVER по адресу 0x0300) как раз и возложена функция переключения задач.
Рассмотрим поэтапно, как это происходит. По прошествии промежутка времени, равного периоду переполнения таймера, произойдет первое прерывание (глобальное прерывание и прерывание от таймера 0, предварительно должны быть разрешены). Допустим, такое случится в точке задачи 1, где содержимое программного счетчика 0x0104, а указателя стека 0x045F. В этот момент значение адреса возврата (PC+1 = 0x0105), аппаратно будет сохранено в стеке. Вершина стека при этом переместится на две позиции вниз (SP-2 = 0x045D) и управление будет передано обработчику прерывания. В конце обработчика, как и при выходе из любой подпрограммы, командой reti адрес возврата будет восстановлен и основная программа продолжит свое выполнение. Но так как стек у AVR, а следовательно и адрес возврата, расположены в общедоступной памяти данных и легко могут быть модифицированы, то появляется возможность осуществить управляемый переход. В начале обработчика service_T0OVER старший байт адреса возврата 0x01 будет находиться по адресу 0x045F, а младший 0x05 по адресу 0x045E. Если перед выходом подменить адрес возврата, например, на 0x0200, что в самом начале и происходит, то программа продолжит свое выполнение с метки task2 т.е. окажется в цикле выполнения задачи 2. Предварительно адрес возврата, конечно, необходимо запомнить. Иначе не удастся вернуться в первоначальное место. Адрес возврата первой задачи сохраняется в ячейках SRAM adr1h:adr1l, адрес второй в adr2h:adr2l. Номер задачи находится в регистре tsknum. Когда наступит второе прерывание (пусть это случится в месте с PC = 0x0205, SP = 0x045F), то, после сохранения в adr2h:adr2l, адрес возврата (PC+1 = 0x0206) будет подменен содержимым adr1h:adr1l = 0x0105 и после выхода программа продолжит выполнение задачи 1 с того места где она была прервана и т.д.
Таким образом, получается, что ОСРВ представляет из себя ни что иное, как обработчик прерываний от таймера, логика работы которого подобна рассмотренному выше примеру. В нашем случае ОСРВ получилась очень простой, но на практике от нее потребуется намного большее действий, чем просто переключение двух задач. Одной из ее функций, как уже говорилось выше, должна быть возможность делить процессорное время в любых соотношениях между всеми задачами. Для этого операционная система может изменять значение счетного регистра TCNT0, регулируя тем самым временной интервал до очередного переполнения.
Перейти к следующей части: Распределение памяти между задачами
 Котов Игорь Юрьевич
Котов Игорь Юрьевич
 Опубликована: 2012 г.
Опубликована: 2012 г.


 Вознаградить
Вознаградить



Комментарии (1) |
Я собрал (0) |
Подписаться
|
Я собрал (0) |
Подписаться
Для добавления Вашей сборки необходима регистрация